

【FDUA】第二回 金融データ活用チャレンジでTableauとDatabricksを使ってみた。

NECネッツエスアイ データ分析チームの豊川です!
前回に引き続き、現在進行形で参加している【FDUA(※)】第二回 金融データ活用チャレンジの取り組みをご紹介します!
データ分析チームのスキルアップを目指して、上位ランクインを目標に🏆
楽しみながらやっていきたいと思います!
応援&いいね👍も、ぜひ!お願いします🤩
※FDUA=金融データ活用推進協会のことです。
本記事は、データ分析をしている人向けの内容になってます😎
もちろん興味ある人にも読んでいただきたいのですが、用語説明などをいつもより省いていますので、検索しながら読んでみてください👀
前回の記事はこちら!
金融データ活用チャレンジについて
「金融データ活用チャレンジ」は、金融データの活用可能性を深化させる業界を挙げた超実践プログラムのデータ分析コンペティションです。
詳細は下記をご覧ください。
はじめに
金融データ活用チャレンジのコンペ内容は、借り手の企業情報や融資金額などの19個の特徴量から、企業向けローンの返済可否を予測する分類モデルの構築です。
私たちのチームではDataiku 、Tableau 、 Dtabriksなどのツールを活用して、コンペにチャレンジしています。
今回の記事では、TableauとDatabricksについて記載します。
Tableau Desktopとは?
Tableau Desktop は、データのアクセス、ビジュアル化、分析に必要なあらゆる機能を備えた、BIツールです。ドラッグ & ドロップ操作の直感的なインターフェイスで、たとえオフラインでも、ビジネス上の意思決定を迅速に行うために必要な隠れたインサイトを引き出すことができます。
Databricksとは?
Databricks は、AI ワークフロー全体のリネージ、品質、制御、データプライバシーの維持が可能な統合分析プラットフォームです。ユースケースを問わず、AI に関わるツールセットの価値を最大化することができます。
Tableauでやったこと
データソースの取込
初めにデータの中身を確認するため、Tableauでデータの可視化を行います。
チームメンバーがDataikuで事前に加工整形したデータを取り込むことによって、Tableaでの前処理を施すことがなくスムーズなデータ可視化ができます。今回はBigqueryにデータを格納して、データの接続を行いました。

シートの作成
テーブルから、「メジャーバリュー、列、行」へデータをドラッグ&ドロップするだけで簡単にデータの集計ができました。
下図のシートでは、データセット内の数値の平均値を表示させています。
青枠内にあるシート単位で、様々な切り口から集計を行ってダッシュボードに表示させるグラフを作成していきます。

ドラック&ドロップするとデータの集計が簡単にできます
ヒストグラムの作成
「メジャーバリュー」の分布を確認するためヒストグラムを作成しました。
このグラフでは「TERM」に分布の偏りがあるため、この偏りを特徴量に加えるのか、を検討しました。
このように分布の偏りにカテゴリ化などを行って特徴量の作成を行います。

箱ひげ図の作成
「メジャーバリュー」の分布をさらに確認するため、目的変数別に箱ひげ図を作成しました。
グラフで確認すると、目的変数別でもフラグ「1」の方に高い数値の外れ値が集まっています。
そこで外れ値の置換処理の検討が必要だと判断し、データ加工フローを見直しました。

ダッシュボードの作成
各シートのグラフをまとめるため、ダッシュボード機能を活用します。
異なるディメンションごとでデータを比較し、生成する説明変数の検討を行いました。
今回は、各ディメンションから統計値を生成して特徴量へ追加しました。また、ダッシュボードから各シートに遷移が可能なので、細かいデータの確認を行いました。
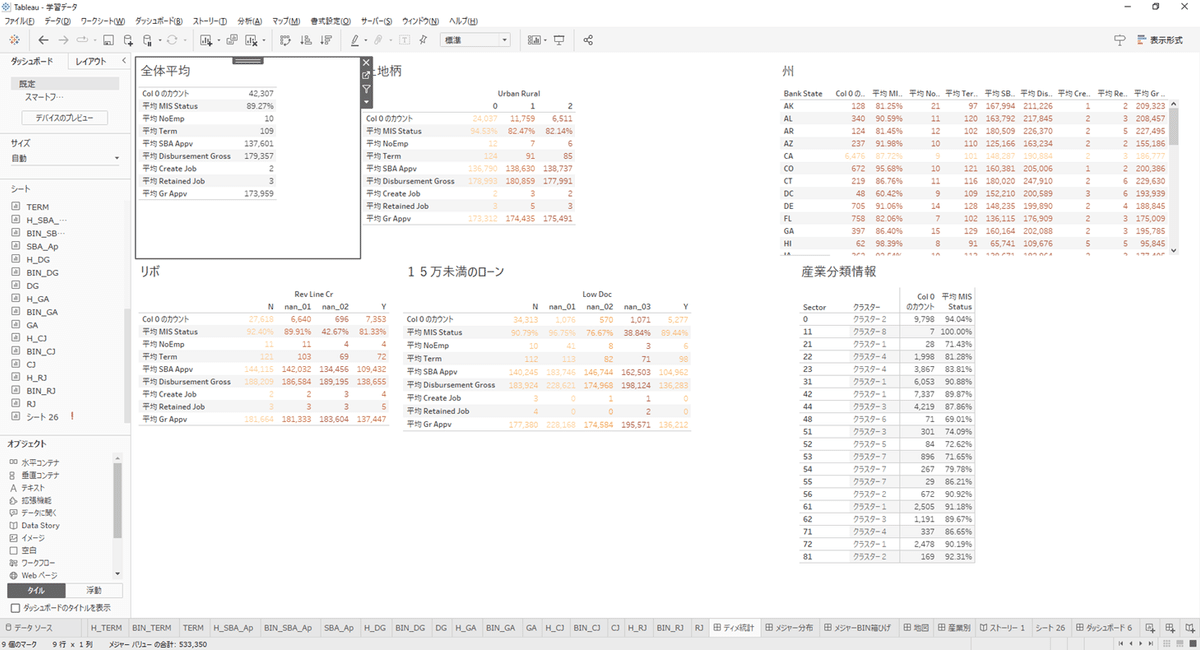
クラスター分析
テーブルの産業分類「0:不明」が「メジャーバリュー」で類似している産業を確認するために、クラスター分析すると「56:行政支援、廃棄物、浄化サービス」と「81:その他(公共行政を除く)」に分類できることが確認できました。このように、クラスター分析では不明な分類を置換する等の検討を行いました。

緯度経度データの可視化
表形式のデータだけでは立地や環境がイメージがしづらい為、Dataikuで「State」単位で緯度経度のデータを生成し、Tableauで地図の読み取り機能をアメリカに設定して可視化を行いました。
ここでは、アメリカの東海岸側で完済する割合が高くなることが視覚的に確認する事ができました。
※参考:Dataikuの緯度経度についてはこちらをご確認ください。

Databricksでやったこと
データを可視化して分析方針を検討してきたので、次にDatabricksを用いてデータ加工とモデル構築を行っていきます。
Databricksではデータカタログ、DWH、AutoMLが1つのプラットフォームにまとまっているので、今回はAutoML機能を利用しました。

インポート
Databricksを利用するために、まずは「カタログ」へデータのアップロードを行います。
アップロードが完了すると「ボリューム」にデータ格納されていることを確認します。「カタログ」からファイルデータとテーブルデータの管理を行います。

データ加工
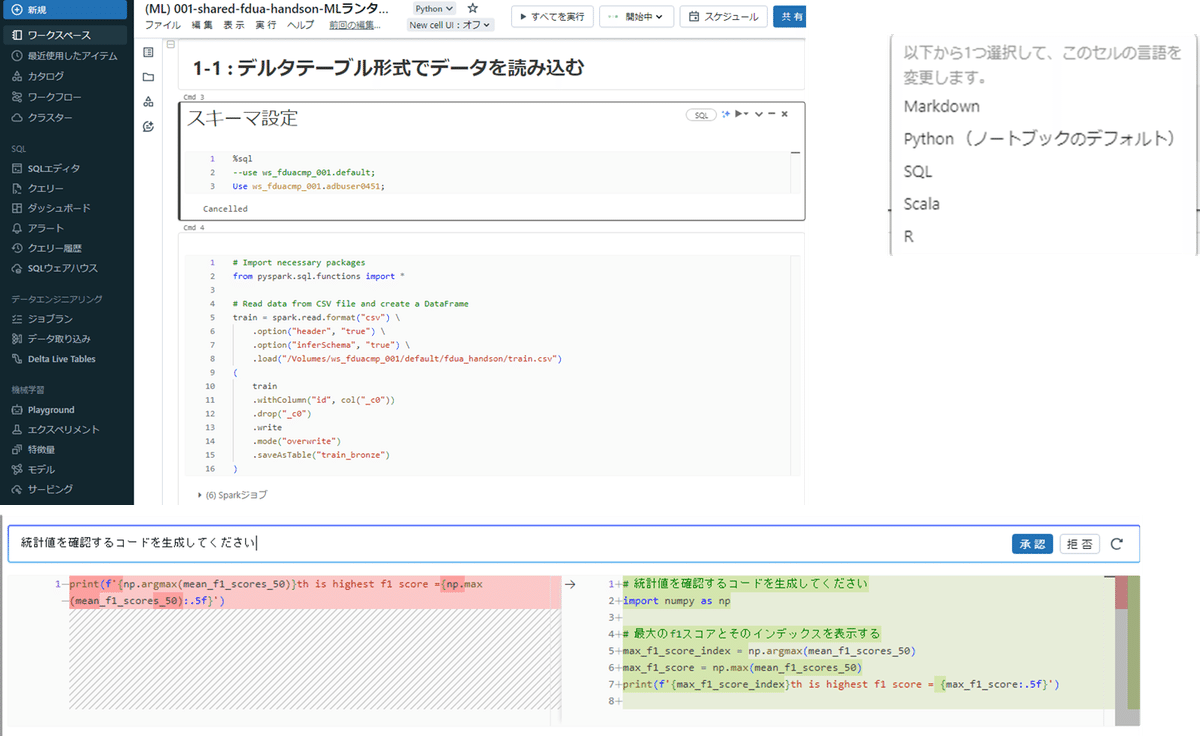
「ワークスペース」からノートブックを起動して、SQLとPythonでインポートしたデータの加工を行いました。
加工の過程で関数などが分からないことがあっても、生成AIのアシスト機能でコードを作成してくれるので、スムーズに作業することができました!
データカタログの作成
SQLでカラムにコメントを付与することで、データカタログを作成することができます。
さらにLLM機能で、テーブルに格納されているデータの内容について、自然言語の説明文を追加することができます。


AutoML機能の利用
「エクスペリメント」から、目的変数「MIS_Status」を予測ターゲットに設定して2値の分類モデルを構築します。モデルはlightgbm、sklearn、xgboostがAutoMLで利用可能です。

AutoMLモデルの構築が完了すると「エクスペリメント」から「最適なモデルのノートブックを表示」でPythonコードが確認できます。この機能を活用すれば、Pythonコードを用いて様々な環境でのモデル実装が可能になります。

モデル構築後は「ワークスペース」のノートブックからAutoMlモデルを適用して、TESTデータを予測します。
AutoMLをGUIベースで構築し、予測の部分はコード環境と分けて取り組む必要がありました。GUIでコードが自動生成されているため、ノートブックにはコードを張り付けるだけの簡単な作業でした。
また、作成したモデルは「モデル」管理機能で管理することが可能です。

オープンデータの活用検討
オープンデータを学習用データセットに付与して、モデル構築の精度に係る変数が利用できるか、を検証しました。
結合キーが「State」単位だったのですが、有効な変数をオープンデータで作成するには、より細かい「City」単位までデータで結合する必要があると感じていました。
オープンデータを追加した前後で比較するために、チームメンバーが採用した変数の設定が必要ですが、dataikuではGUIで選択する変数のコピー機能がありとても便利でした。
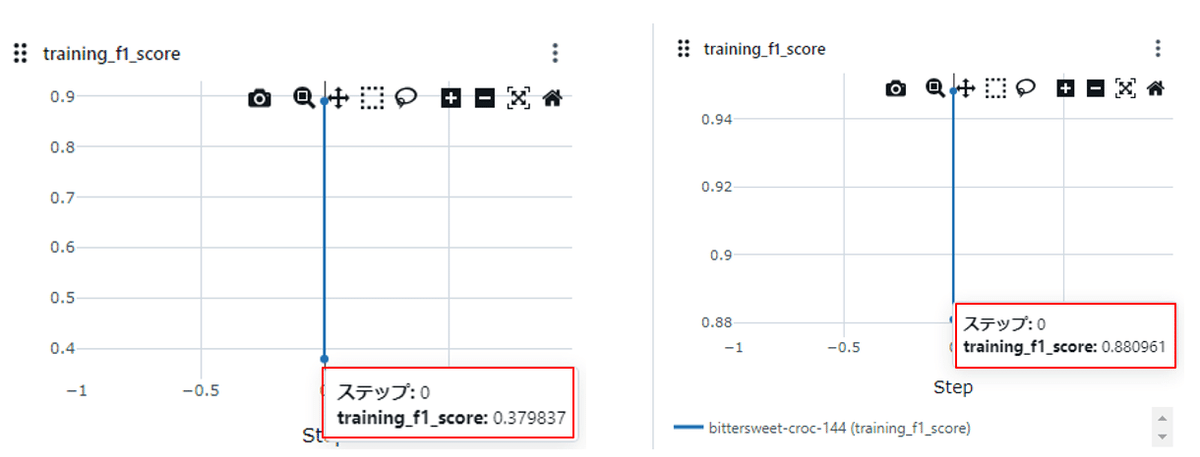
学習データのF1スコアについても、オープンデータ側が「State」単位で紐づけるだけだとスコア向上にならないことが確認できました。
LLM機能
最後にLLM機能を利用しました。
システムプロンプトで「日本語で回答して」と指定しているのですが、結果は英語で出力されました。このような細かい精度向上にむけた開発は、これから行われるのかと思いましたが、英語で記載された文章を確認した所、システムプロンプトで入力した通りのアドバイスを出力することができました。

あるあるですね、、、
まとめ
今回はDataiku、Taleau、Databriksとコンペで提供された3つのツールを活用したのですが、それぞれのツールに独自な強みがあると私は思いました。
Tableauの強み
Tableauは、重い生データよりも加工済みデータをデータソースとして利用することで、レスポンスよくストレスを感じずにデータを可視化できます。
ちょっと気になるデータを手早くグラフ化できるので、どのような分布なのか、スピーディーに確認することができます。
Databriksの強み
Databriksのデータ管理のカタログ機能は、生成AIにより自然言語でのデータセットの状況を提示してくれます。カタログ機能を利用することで、初めてデータを見る人でも何となくどんなデータなのか簡単に把握することができました。
またAutoMLの結果をPythonコードで出力できるので、各種ツールと連携して同等のモデルが実装できる部分が魅力的でした。データベースとデータカタログ、AutoMLが1つのパッケージであるツールだと思いました。
Dataikuについて
最後に
チャレンジ内容の詳細は、順次UPしていきたいと思います。
私たちチームは駆け出しのデータ分析チームです🔰
皆様のアドバイスも、ぜひぜひよろしくお願いします!めざせSilver🥈!?
今回のSIGNATE 第2回 金融データ活用チャレンジ 参加メンバー
小林哲
市川銀次
豊川絢基(執筆者)
南侑志
鈴木良太郎(執筆者)

次回もお楽しみに!

最後までお読みいただきありがとうございます!
