

【FDUA】第二回 金融データ活用チャレンジにDataikuを活用して参加してみる。

NECネッツエスアイ データ分析チームの鈴木(良)です!
今回は、現在進行形で参加している【FDUA(※)】第二回 金融データ活用チャレンジの取り組みをご紹介します!
データ分析チームのスキルアップを目指して、上位ランクインを目標に🏆
楽しみながらやっていきたいと思います!
応援&いいね👍も、ぜひ!お願いします🤩
※FDUA=金融データ活用推進協会のことです。
本記事は、データ分析をしている人向けの内容になってます😎
もちろん興味ある人にも読んでいただきたいのですが、用語説明などをいつもより省いていますので、検索しながら読んでみてください👀
金融データ活用チャレンジについて
「金融データ活用チャレンジ」は、金融データの活用可能性を深化させる業界を挙げた超実践プログラムのデータ分析コンペティションです。
詳細は下記をご覧ください。
はじめに
金融データ活用チャレンジのコンペ内容は、借り手の企業情報や融資金額などの19個の特徴量から企業向けローンの返済可否を予測する分類モデルの構築です。
今回はDataikuなどのAutoMLツールを活用して、コンペにチャレンジしています。
Dataikuとは?
Dataikuはデータソースへの接続からデータの準備・加工、AIや機械学習モデルの自動生成に加え、分析アプリケーションの開発と運用まで、一連の処理をひとつのソリューションとして統合させた、オールインワン AI・機械学習プラットフォームです。

Dataikuの利用方法と特徴を簡単にご紹介します。
「レシピ」いう入力データセットに対して、実行するアクションセットを利用すれば、ノーコードでも分析を行うことが可能です。
このため、プログラミングを勉強し始めた方でも、簡単にモデリングからモデルのデプロイまで行うことができます。
また、Notebook環境が搭載されており、Dataikuに搭載されていない機能もPythonなどで直接プログラムを書くことで実装できるため、プログラミング経験が豊富な方にも、もちろんお勧めできるツールです。
取り組み
Dataiku上でデータセットの前処理からモデリング、提出用のデータセットの出力まで実施したので、その取り組みを本記事で共有します。
基本的に、前処理にはPythonコネクタを用いてプログラミングで実装し、モデリングはDataikuのAutoMLを用いました。
前処理はDataikuのPrepareレシピ(※下図の赤枠)を用いて、実装することも可能だと思います。が、エンコーディングなど学習用データしか使えない処理もあり、多少複雑な処理が必要のため、Pythonコネクタでまとめて実装することにしました。

結合やデータの分割など分析に必要な処理が
上記のアイコンのコネクタから直感的に実装することができます。
Dataikuフロー
Dataikuフローは、パイプラインを視覚的に表現したもので、全ての作業内容が視覚的に集約されています。なので、プロジェクトを簡単に管理することが可能です。また、チームメンバーで同一フローを共有できるため、スムーズに共同作業を行うことができます。
レシピをいくつも実行するとフローが複雑化しますが、Zoneという機能を用いることで、フローに並べられたレシピをグループ化してフローの中で各処理がどのような意味があるのかを整理することができます。すべての作業とプロジェクトの知識が1つの場所に集約されているため、新しいチームメンバーとの連携や変更点の把握が容易になります。

いろいろなモデルを作成しましたが、一覧を直感的に把握することができます。
本記事では赤枠内をご説明しています。
前処理
まずは、インプットデータの前処理についてです。
前処理は学習データとテストデータの両方で行うために、Pythonコネクタを使用して同時に処理しています。Pythonコネクタを使用するには、trainのデータセットとtestのデータセットの2つを選択した状態で右のCode recipesのPythonを選択することで使用可能です。
また、後半の赤いアイコンのレシピはDataikuのGeoCoderというプラグイン機能を用いて、都市名からその都市の緯度経度を出力しています。(次のパートで説明します。)

Dataikuでデータセットをインポートする学習データとテストデータで共通の処理を行うのでデータをスタックします。
DataikuでNotebookを編集すると、以下のライブラリが自動的に入力されます。
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pduDataikuというライブラリのDatasetメソッドを用いてデータセットをデータフレーム形式で呼び出しています。
# Read recipe inputs
df_train = dataiku.Dataset("train").get_dataframe()
df_test = dataiku.Dataset("test").get_dataframe()
print(f'trainデータ数:{df_train.shape}', f'testデータ数:{df_test.shape}')学習データとテストデータをconcat関数で結合しています。
# trainデータとテストデータのフラグを付けてユニオンする
df_train_target = df_train['MIS_Status'].values
df_train = df_train.drop(columns='MIS_Status', axis=1)
df_train['flag'] = 'train'
df_train['MIS_Status'] = df_train_target
df_test['flag'] = 'test'
df_test['MIS_Status'] = 999 # 仮の数字(あとで削除するのでなんでもOK)
df = pd.concat([df_train, df_test], axis=0)データの型変換
①表示上では数値データとなっているがカテゴリの扱いのデータを
カテゴリデータに変換
②日付データを扱いやすいように変換(31-Jan-98 → 1998-01-31 )
③金額データに「$」が入っていたので、取り除いて数値データに変換
# col_0(識別ID)、FranchiseCode(フランチャイズCD)、Sector(産業分類CD), Urban(地方都市CD)はカテゴリ化
df[['col_0', 'FranchiseCode', 'Sector', 'category']] = df[['col_0', 'FranchiseCode', 'Sector', 'category']].astype('category’)
# NewExistは、カテゴリ変数に変換(新規ビジネスかどうか*1 = 既存のビジネス、2 = 新規ビジネス)
df['NewExist'] = df['NewExist'].astype(int).astype('category')
# MIS_Statusはカテゴリ変数に変換
df['MIS_Status'] = df['MIS_Status'].astype(int).astype('category')
# DisbursementDate はyyyy-mm-dd形式に変換
df['DisbursementDate'] = pd.to_datetime(df['DisbursementDate'], format='%d-%b-%y')
df['DisbursementDate'] = df['DisbursementDate'].dt.strftime('%Y-%m-%d')
df['DisbursementDate'] = pd.to_datetime(df['DisbursementDate'])
# ApprovalDate はyyyy-mm-dd形式に変換
df['ApprovalDate'] = pd.to_datetime(df['ApprovalDate'], format='%d-%b-%y')
df['ApprovalDate'] = df['ApprovalDate'].dt.strftime('%Y-%m-%d')
df['ApprovalDate'] = pd.to_datetime(df['ApprovalDate’])
# ドルを取り除き、数値データに変換
df[['DisbursementGross', 'GrAppv', 'SBA_Appv']] = df[['DisbursementGross', 'GrAppv', 'SBA_Appv']].applymap(lambda x: x.strip().replace('$', '').replace(',', ''))
欠損値の処理
「RevLineCr」カラム、「LowDoc」カラム、「DisbursementDate」カラム、「BankState」カラムに欠損値が見受けられます。欠損値の処理はDataikuのAutoMLフェーズでも可能ですが、平均値や最頻値、中央値で補完などの機能しかないので、今回はNotebook上で欠損項目の分布の割合から手動で処理しました。

まずは、 「RevLineCr」カラムのカテゴリごとの目的変数のクラス分布を確認してみます。
PythonのMatPlotlibやSeabornを使えば確認可能ですが、今回はDataikuのCharts機能を用いて可視化してみます。Chartsはフローのデータセットを選択し、下図のChartsタブからグラフの作成が可能です。

Chartsでは基本的なグラフ機能が搭載されており、簡易的なデータを可視化できます。作成したグラフはダッシュボードとして出力することもできます。
「RevLineCr」は「リボルビング信用枠かどうか」を意味するカラムで、Y(はい)とN(いいえ)の二値をとるはずです。しかし、データを確認すると欠損値以外にも、Tや0といったノイズが含まれています。今回はTや0も別の値に置き換えることにします。それぞれの分布を確認してみましょう。
0とNoValueは分布の傾向が似ており、一方でTは他のカテゴリのいずれとも異なりそうなので、 それぞれ区別できる形で欠損という情報を埋め込みます。とりあえず、0とNoValueは「nan_01」、Tは「nan_02」と欠損値を補完しました。
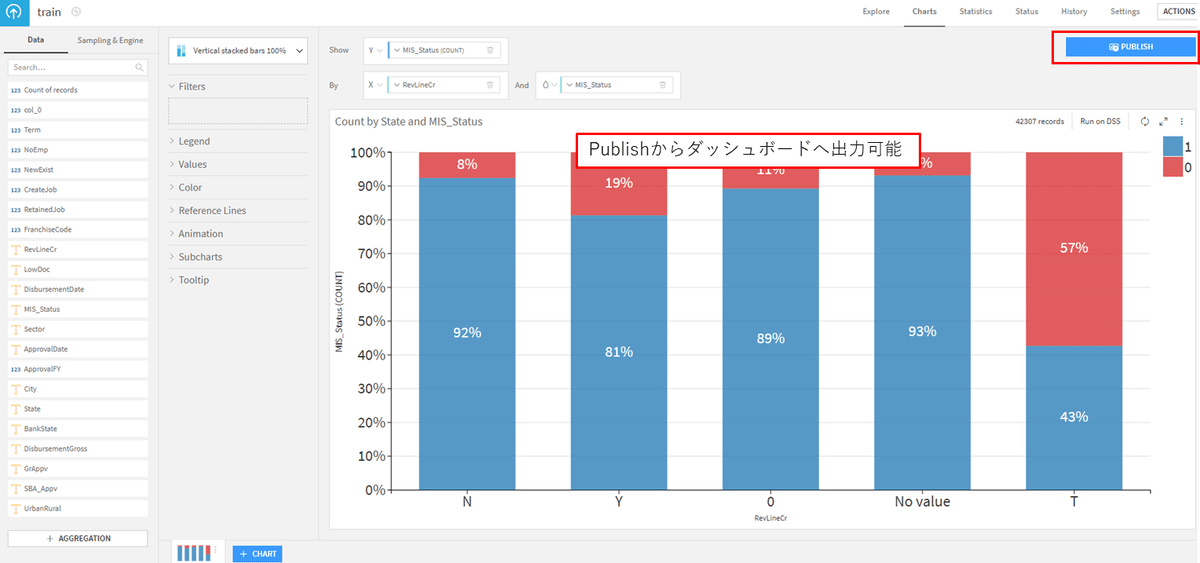
# 0とNovalueは目的変数の分布傾向が似ている(目的変数の割合0:1 = 1:9)なので、同じ値で代入(nan_01)
# Tは目的変数の分布が通常と異なるの別の値で補完する(nan_02)
df['RevLineCr'] = df['RevLineCr'].fillna('nan_01') # '0'もしくはNaNの場合に'nan_01'で補完
df['RevLineCr'] = np.where(df['RevLineCr'] == '0', 'nan_01', df['RevLineCr']) # '0'もしくはNaNの場合に'nan_01'で補完
df['RevLineCr'] = np.where(df['RevLineCr'] == 'T', 'nan_02', df['RevLineCr']) # 'T'の場合に'nan_02'で補完次に、 「LowDoc」カラムのカテゴリごとの目的変数のクラス分布を確認してみます。
「LowDoc」は「15万ドル未満のローンを1ページの短い申請で処理できるプログラムか」を意味するカラムで、Y(はい)とN(いいえ)の二値をとるデータです。
しかし、こちらも欠損値以外にも0、A、S、Cといったノイズが含まれていることがわかります。「RevLineCr」と同じように分布ごとに欠損の情報を埋め込んでいきます。
分布を確認すると0とCは目的変数が0の割合が非常に少なくなっています。一方、SとNoValueは目的変数が0の割合が半分以上となっています。また、Aはその中間のような分布となっています。そのため、0とCは「nan_01」、Aは「nan_02」、SとNoValueは「 nan_03」と欠損値を補完します。

# 0とcは目的変数の分布傾向が似ている(1の割合が99%程度)なので、同じ値で代入(nan_01)
# Aは目的変数の分布が通常と異なるの別の値で補完する(nan_02)
# SとNo valueは目的変数の分布が通常と異なるの別の値で補完する(nan_03)
df['LowDoc'] = df['LowDoc'].fillna('nan_03')
df['LowDoc'] = np.where(df['LowDoc'] == 'S', 'nan_03', df['LowDoc'])
df['LowDoc'] = np.where(df['LowDoc'] == 'A', 'nan_02', df['LowDoc'])
df['LowDoc'] = np.where(df['LowDoc'] == '0','nan_01', df['LowDoc'])
df['LowDoc'] = np.where(df['LowDoc'] == 'C','nan_01', df['LowDoc']) 「 DisbursementDate (融資の支払日)」カラムは「 ApprovalFY (承認された財務年度)」ごとのDisbursementDateの最頻値の値で補完します。
# ApprovalFYごとにDisbursementDateの最頻値を計算
df['DisbursementDate'] = pd.to_datetime(df['DisbursementDate']) # DisbursementDateをdatetime型に変換
# NaTをApprovalFY年度ごとの最頻値で補完する
df['DisbursementDate'] = df.groupby('ApprovalFY')['DisbursementDate'].transform(lambda x: x.mode().iloc[0] if not x.mode().empty else pd.NaT)「 BankState 」カラムは欠損値の数が27件と非常に少ないので、 「State」カラムの値で補完することにします。
# BankStateがNaNのデータをStateカラムの値で補完
df['BankState'] = df.apply(lambda row: row['State'] if pd.isna(row['BankState']) else row['BankState'], axis=1)その他、後の処理でDataikuのプラグインのGeoCoderを用いる際に必要な、都市を識別するカラムを作成します。こちらの作業をせずにGeoCoderを行うと同名の別の都市の緯度経度を出力したので、処理を追加しています。
例えば、アメリカのイリノイ州にPekin(ピーキン)という都市がありますがPekinのままGeoCoderを行うと中国の北京(ペキン)の緯度経度を出力したため都市の接頭に「United State of America 」を追加しました。
# GeoCodeでr緯度経度を出力するために、「Countpry+city」カラムを作成する。
df['Coountry_City'] = 'United State of America ' + df['City']出力用の学習データとテストデータに再度分割する
df_train = df[df['flag']=='train']
df_trian = df_train.drop(columns='flag', axis=1)
df_test = df[df['flag']=='test']
df_test = df_test.drop(columns=['flag', 'MIS_Status'], axis=1)Dataikuのフローに再度出力する
# Write recipe outputs
train_preprocessing = dataiku.Dataset("train_preprocessing")
train_preprocessing.write_with_schema(df_trian)
test_preprocessing = dataiku.Dataset("test_preprocessing")
test_preprocessing.write_with_schema(df_test)Dataikuプラグインを用いた緯度経度の出力
プラグインを用いるとDataiku DSSに新たな機能をアドオンすることができます。Dataiku社のPluginsサイトでさまざまな機能のプラグインが提供されています。(プラグインはこちらで確認可能です。)Dataikuプラグインを利用するには、プラグインをインストールする必要があります。
操作画面右上のPluginsタブからインストールが可能です。

左の検索ウィンドから「geocoder」と入力すると検索結果が表示されるので、INSTALLをクリックすると自分の環境でインストールしたプラグインを使用することが可能になります。

学習データとテストデータでGeocoderプラグインを用いて、都市名から緯度と経度を取得します。(処理に少し時間がかかります。)


出力されたテーブルを確認すると緯度(latitude)と経度(longitude)が出力されました。Chartでマップチャートを作成するには、PrepareレシピからGeopointを作成する必要がありますが、今回は割愛します。
(こちらの記事が参考になるかと思います。)
ここまでで、データの前処理が完了しました。
それでは、AutoMLを用いて企業のローンの返済を予測してみましょう。

AutoMLは対象のデータセットをクリックして、LABから実行することができます。予測や時系列分析、クラスタリングなど様々な予測対象に合わせたモデリングが可能です。
今回は、AutoML Predictionから分類モデルを作成しました。

モデリング
目的変数の分布の確認
今回のデータは、0(不履行)が10%、1(完済)が90%の不均衡データです。一般的に不均衡データはリサンプリングやSMOTEなどの生成モデルを使用することがよくあります。
今回はアンダーサンプリングをすることで、2つのクラスが同じ割合になるように調整してみます。

学習データと検証データの分割
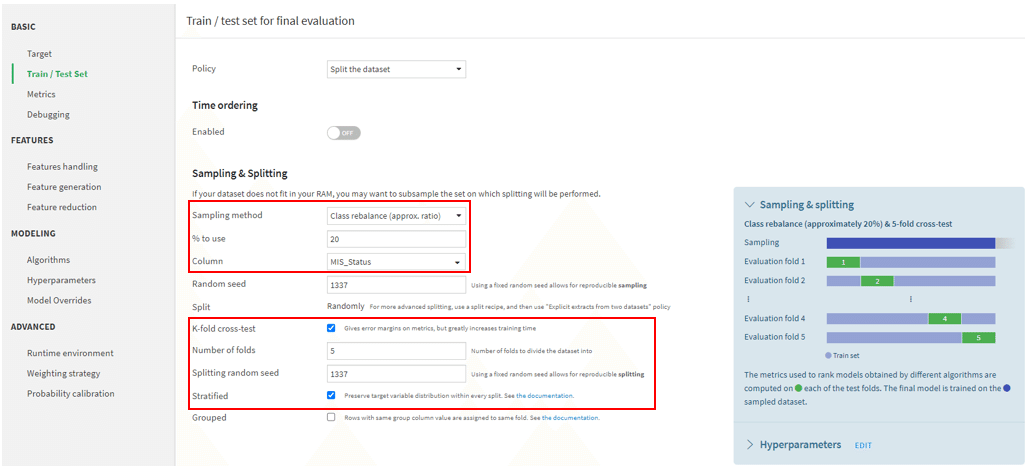
Train/Test Setから学習データと検証用データの分割を設定することができます。今回設定した情報は下図の赤枠になります。
「Sampling method」はクラスの割合が同じになるように分割するClass rebalance(approx. ratio)を選択します。「% to use」はデータの何%を使用するかを設定する項目で、今回は20%を選択しました。学習データが42307件でそのうちの20%を使用すると、8500件弱使用することになります。学習データのクラス0は約4500件、クラス1は約4000件なので、クラスの割合はほぼ1:1になります。「K-fold」でクロスバリデーションを5に設定し、「Stratified」にチェックを入れます。
特徴量の選択
Features handlingから特徴量の選択が可能です。ON/OFFからモデリングに用いる特徴量を選択することができます。
例えば、「NewExist」は新規ビジネスかどうかを表すフラグです。数値に意味がないのでカテゴリ変数として扱うことにします。
また、カテゴリ変数は一般的にエンコーディングを行う必要があります。エンコーディングはCategory handlingから選択可能で、ダミーコーディングやターゲットエンコーディング、Ordinalエンコーディングなどから選択可能です。今回はダミーエンコーディングを行うことにします。

機械学習モデルの選択
Algorithmからモデルのアルゴリズムの設定が可能です。
Random Forest、Light GBM、Decision Treeの3つのモデルで精度を比較してみたいと思います。各アルゴリズムのハイパーパラメータはデフォルト値を用います。モデルの学習は、右上のTRAINから実行可能です。

モデルの評価
各モデルの精度はモデルをクリックすることで確認可能です。Light GBMの予測結果を確認してみましょう。

特徴量の重要度
Feature importanceから特徴量の重要度が確認可能です。今回のモデルでは、UrbanRulalの重要度が高いことがわかります。

また、Shapley値から各特徴量が予測にどれだけの影響を与えるかを確認することが可能です。
※Shapley値についてはこちらの記事が参考なるかと思います。

検証用データの予測精度の評価
検証データの評価はConfusion matrixから確認可能です。
今回のコンペの評価指標であるF1スコアは73%となりました。右上のThresholdから閾値の調整が可能で、今回は0.35以上のデータは1になるように予測しています。

モデルのデプロイ
モデルのデプロイは画面右上のDEPLOYから可能です。
新規のモデルを作成する際は、「Deploy as a new retrainable model」を
既存のモデルをアップデートする際は「Update existing training recipe」を選択します。

テストデータの予測と提出ファイルの出力
テストデータの予測
デプロイしたモデルを使ってテストデータを予測したい場合は、対象のデータセットをクリックし、Predictレシピを選択します。
先ほどデプロイしたモデルの選択と出力先のテーブル名の作成し、Runで予測を実行します。

作成されたデータセットを確認すると、Predictionカラムと0と1の予測率のカラムが追加されています。

提出ファイルの出力
提出時に必要なカラムは識別IDのcol_0とPredictionカラムだけなので、それらをPythonコネクタを用いて出力します。
Notebook上で以下のコードを実行すると、sample_submission.csvファイルと同じ形式のデータを出力することができます。

# -*- coding: utf-8 -*-
import dataiku
import pandas as pd, numpy as np
from dataiku import pandasutils as pdu
# Read recipe inputs
df = dataiku.Dataset("test_geo_scored").get_dataframe()
submission_df = df[['col_0', 'prediction']]
submission_df.rename(columns={'prediction': 'col_1'}, inplace=True)
submission_basemodel = dataiku.Dataset("submission_basemodel")
submission_basemodel.write_with_schema(submission_df)データの出力はデータセットを選択した状態でExportクリックすると可能です。

まとめ
Dataikuを用いることで、非常に簡単に前処理からテストデータの予測までできました。
今回は、一部Pythonコネクタを用いていますが、PrepareレシピやStackレシピ、Splitレシピを使うことで完全ノーコードで実装することも可能です。
また、必要最低限の前処理やハイパーパラメータもデフォルト値を用いているので、スコアはPublicボードのスコアは0.68弱程度になるはず(?)ですが、特徴量追加やハイパーパラメータの最適化、バリデーション、など工夫することでスコアの改善も見込めるかと思います。
最後に
チャレンジ内容の詳細は、順次UPしていきたいと思います。
私たちチームは駆け出しのデータ分析チームです🔰
皆様のアドバイスも、ぜひぜひよろしくお願いします!めざせSilver🥈!?
今回のSIGNATE 第2回 金融データ活用チャレンジ 参加メンバー
小林哲
市川銀次
豊川絢基
南侑志(執筆者)
鈴木良太郎(執筆者)

次回もお楽しみに!

最後までお読みいただきありがとうございます!
